RAG Complete Guide
Tools · 10 min

RAG (Retrieval Augmented Generation) kombiniert Information Retrieval mit Text Generation. Das LLM kann so auf dein eigenes Wissen zugreifen — statt nur auf seine Trainingsdaten.
Warum RAG?
- LLMs wissen nicht alles — besonders nicht dein Wissen
- Trainings-Daten sind veraltet — RAG nutzt aktuelle Dokumente
- Kein Prompt-Engineering für jeden Use Case nötig
- Zitate und Quellen sind nachvollziehbar
- Datenschutz: Deine Dokumente verlassen nie deine Infrastruktur
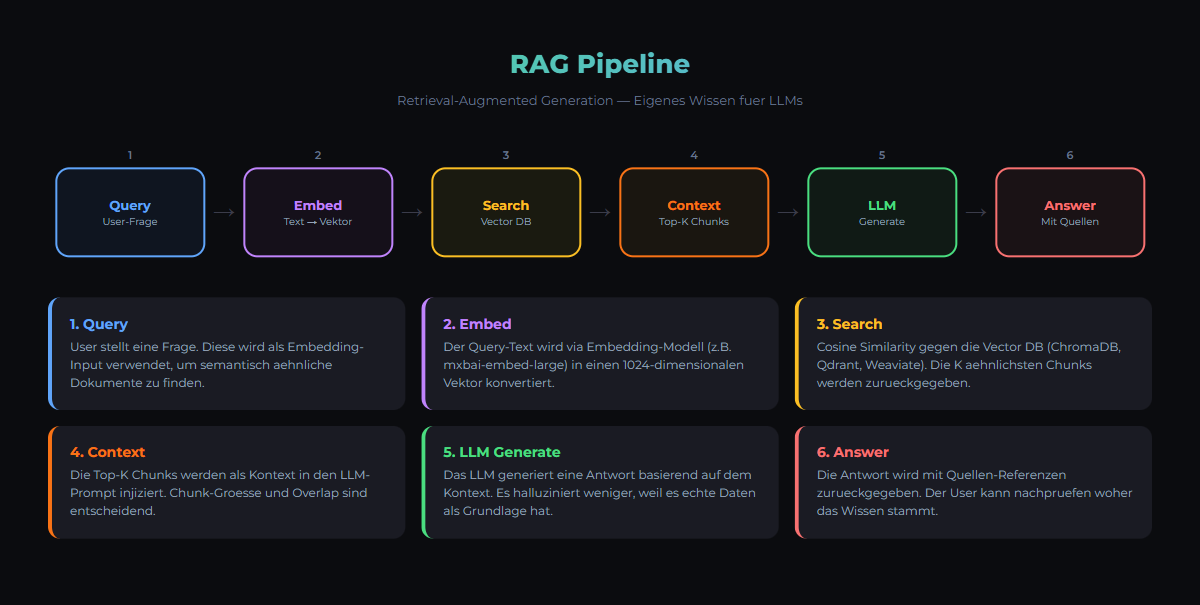
RAG Workflow
Phase 1: Offline (einmalig)
- Document Chunking: Dokumente in kleinere Teile splitten (256-512 Tokens)
- Embedding: Chunks in numerische Vektoren umwandeln
- Indexing: Vektoren in durchsuchbare Datenbank speichern
Phase 2: Online (bei jeder Query)
- Query Embedding: User-Frage in Vektor umwandeln
- Retrieval: Ähnlichste Dokument-Chunks finden
- Augmented Generation: LLM generiert Antwort basierend auf Query + Chunks
Vector Databases
| Database | Typ | Vorteile | Nachteile |
|---|---|---|---|
| ChromaDB | Open Source | Einfach, Python-nativ | Weniger Features |
| Weaviate | Open Source | Hybrid Search, GraphQL | Komplexer |
| Qdrant | Open Source | Schnell, Rust-basiert | Jünger, weniger Docs |
| Pinecone | Managed Cloud | Zero Ops, skalierbar | Kosten, nicht lokal |
| Neo4j | Graph + Vektor | Beziehungen wichtig | Ressourcen-intensiv |
Embedding Models
| Model | Dimensionen | Kosten | Lokal? |
|---|---|---|---|
| text-embedding-ada-002 | 1536 | $0.0001/1K Tokens | Nein |
| text-embedding-3-large | 3072 | $0.00013/1K | Nein |
| all-MiniLM-L6-v2 | 384 | Kostenlos | Ja |
| all-mpnet-base-v2 | 768 | Kostenlos | Ja |
| mxbai-embed-large | 1024 | Kostenlos | Ja (Ollama) |
Best Practices
- Chunk Size: 256-512 Tokens — Balance zwischen Kontext und Präzision
- Overlap: 50-100 Tokens — Kontext geht nicht verloren an Chunk-Grenzen
- Hybrid Search: BM25 (Keyword) + Semantische Suche kombinieren
- Reranking: Cross-Encoder nach initial Retrieval für bessere Ergebnisse
- Metadata Filtering: Filter nach Datum, Autor, Kategorie ermöglichen
Einfaches RAG Setup mit Ollama
# 1. Ollama mit LangChain/LlamaIndex
pip install langchain langchain-community llama-index
# 2. Einfaches RAG mit LangChain
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_ollama import ChatOllama
from langchain.chains import RetrievalQA
# Dokumente laden
loader = TextLoader("meine_dokumente.txt")
docs = loader.load()
# Chunking
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(docs)
# Embedding + Vector Store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(chunks, embeddings)
# QA Chain
llm = ChatOllama(model="llama3.2")
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff",
retriever=vectorstore.as_retriever())
# Query
result = qa.run("Was steht in meinen Dokumenten?")
print(result)Erwartete Ausgabe:
# Beispielausgabe:
# "In Ihren Dokumenten geht es um die Projektplanung für Q1 2026.
# Die Hauptpunkte sind: Budgetfreigabe, Team-Ressourcen und
# Meilenstein-Definitionen."Hybrid RAG: BM25 + Vektor
Für beste Ergebnisse kombinieren wir keyword-basierte Suche (BM25) mit semantischer Suche:
# Hybrid Search mit LangChain
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_community.retrievers import BM25Retriever
# BM25 Retriever (Keyword)
bm25_retriever = BM25Retriever.from_documents(chunks)
# Vector Retriever (Semantic)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# Beide kombinieren
from langchain.retrievers import EnsembleRetriever
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)
# Fusion Retrieval (neuere Alternative)
# Alle Ergebnisse mischen und nach Score neu sortierenFortgeschritten: Query Transformations
Du kannst die Query vor dem Retrieval verbessern:
# Multi-Query Retrieval
from langchain.retrievers.multi_query import MultiQueryRetriever
# Generiert mehrere Varianten der User-Query
# und führt alle Retrievals zusammen
retriever = MultiQueryRetriever.from_llm(
retriever=vector_retriever,
llm=llm
)
# Step-back Prompting
from langchain.prompts import PromptTemplate
step_back_prompt = PromptTemplate.from_template("""
Du bist ein hilfreicher Assistent.
Frage allgemeiner formuliert: {question}
""")
# HyDE (Hypothetical Document Embeddings)
# LLM generiert hypothetische Antwort → embedden → RetrievalUnser Hybrid RAG Stack
Wir nutzen:
- • ChromaDB — Vector Store (einfach, Python-nativ)
- • Neo4j — Knowledge Graph für Beziehungen
- • BM25 — Keyword-Suche via Whoosh
- • nomic-embed-text — Lokales Embedding Model
- • LlamaIndex — RAG Framework
- • Ollama — Lokales LLM für Generation
Zusammenfassung
RAG ist der Schlüssel zu lokalen AI-Systemen, die auf dein Wissen zugreifen können. Mit ChromaDB + Ollama hast du ein einfaches Setup. Für Produktion empfehlen wir Hybrid Search (BM25 + Vektor) + Reranking für beste Ergebnisse.
Quellen
- LangChain RAG Tutorial — Offizielle LangChain-Dokumentation zu RAG
- LlamaIndex Docs — RAG Framework Dokumentation
- ChromaDB Docs — AI-native Embedding-Datenbank
- Qdrant Documentation — High-Performance Vector Search
- Ollama — Lokale LLM Runtime
Weiterfuehrende Artikel: Ollama Tutorial · Was ist ein LLM? · n8n Workflow Bundle
Fuer die Umsetzung gibt es Ressourcen auf ai-engineering.at.
War dieser Artikel hilfreich?
Nächster Schritt: Workflows sauber in Betrieb bringen
Nutze bewährte n8n-Patterns, Templates und Integrationen für Workflows, die lokal, dokumentiert und auditierbar bleiben.
- Lokal und self-hosted gedacht
- Dokumentiert und auditierbar
- Aus eigener Runtime entwickelt
- Made in Austria