Model Selection Guide
Wähle das richtige AI-Modell für deinen Anwendungsfall.
Stand: März 2026
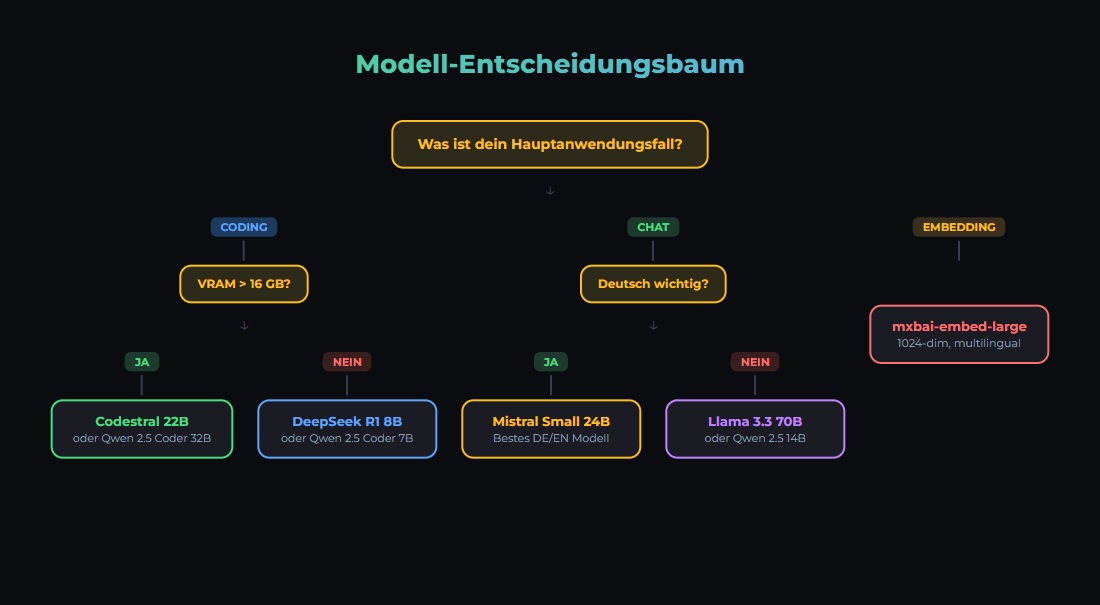
Diagramm wird geladen...
Die Entscheidung
Die Wahl des richtigen Modells ist der wichtigste technische Entschluss. Falsches Modell = schlechte Ergebnisse oder unnötige Kosten.
Modell-Kategorien
1. Small Models (1-3B Parameter)
- Beispiele: Llama 3.2 1B/3B, Gemma 2 2B, Phi-3.5 Mini
- Hardware: CPU reicht, 4-6GB RAM
- Latenz: <100ms
- Use Cases: Embeddings, Klassifikation, einfache Q&A
2. Medium Models (7-14B Parameter)
- Beispiele: Llama 3.3 8B, Qwen3 14B, Gemma 2 9B
- Hardware: 16GB RAM, GPU empfohlen (8-16GB VRAM)
- Speed: 43-112 tok/s auf RTX 3090
- Use Cases: Chat, Zusammenfassungen, Code-Generation, Tool Calling
3. Large Models (24B-34B Parameter)
- Beispiele: Mistral Small 3.1 (24B), Qwen 2.5 32B
- Hardware: 24GB VRAM (RTX 3090/4090)
- Speed: ~20-30 tok/s auf RTX 3090
- Use Cases: Komplexe Reasoning, lange Dokumente, höchste lokale Qualität
- Hinweis: 70B Modelle passen NICHT auf 24 GB VRAM — brauchen 48 GB+ oder Multi-GPU
4. Top Open Source (S-Tier, März 2026)
- GLM-5 (Z AI): Reasoning-Spezialist, GPQA Diamond 86%, HumanEval 90%, SWE-bench 77.8%
- Kimi K2.5 (Moonshot AI): HumanEval 99%, AIME 96.1%, SWE-bench 76.8% — S-Tier
- MiniMax M2.5: S-Tier im Artificial Analysis Leaderboard
- Qwen 3.5 Plus: MMLU 88.4%, ~1/13 der Kosten von Claude Sonnet

Vergleichstabelle (Stand März 2026)
| Modell | Parameter | VRAM (Q4) | tok/s (RTX 3090) | Stärke |
|---|---|---|---|---|
| Gemma 2 2B | 2B | ~2 GB | 200+ | Embeddings, Klassifikation |
| Llama 3.3 8B | 8B | ~5 GB | ~112 | Allrounder, schnell |
| Qwen3 14B | 14B | ~10 GB | 43.2 | Deutsch, multilingual |
| Mistral Small 3.1 | 24B | ~16 GB | ~30 | Deutsch (übertrifft GPT-4o Mini) |
| Qwen 2.5 32B | 32B | ~20 GB | ~20 | Coding, Reasoning |
| Llama 3.3 70B | 70B | ~40 GB | Braucht 48 GB+ | MMLU 86%, HumanEval 88.4% |
Deutsch-Tipp: Mistral Small 3.1 (24B) übertrifft GPT-4o Mini und Gemma 3 bei europäischen Sprachen — ideal für deutschsprachige Chat- und Content-Tasks auf lokaler Hardware.

Hardware-Anforderungen mit Ollama
Hier ist, was du brauchst um die Modelle lokal zu betreiben:
# Ollama Modelle laden und testen
ollama pull llama3.2
# Modelle auflisten
ollama list
# Mit Modell chatten
ollama run llama3.2 "Hallo, wer bist du?"
# Hardware check
ollama run llama3.2 "Wie viel RAM hast du verwendet?"Typische RAM-Belastung bei Ollama:
# VRAM Verbrauch (ca., Q4 quantisiert)
gemma2:2b ~2GB VRAM → 200+ tok/s
llama3.3:8b ~5GB VRAM → ~112 tok/s
qwen3:14b ~10GB VRAM → 43 tok/s
mistral-small3.1:24b ~16GB VRAM → ~30 tok/s
qwen2.5:32b ~20GB VRAM → ~20 tok/s
llama3.3:70b ~40GB VRAM → PASST NICHT auf 24GB GPU!
# RTX 3090 (24 GB): Maximum ist ca. 34B (Q4_K_M)
# 70B braucht 48 GB+ (2x RTX 3090 oder RTX 6000 Ada)
# Mit quantized Modellen sparen
ollama pull llama3.3:q4_K_M # 4-bit Quantisierung, ~5GB
ollama pull qwen3:14b # 4-bit default, ~10GBEntscheidungshilfe
- Budget gespart? → Llama 3.3 8B oder Qwen 2.5 7B (~112 tok/s auf RTX 3090)
- Maximale lokale Qualität? → Mistral Small 3.1 24B oder Qwen 2.5 32B (passt auf 24 GB)
- Schnelle Embeddings? → mxbai-embed-large (1024 dim)
- Deutsch? → Mistral Small 3.1 (übertrifft GPT-4o Mini) oder Qwen3 14B
- Absolut beste Qualität? → Cloud API: Claude Sonnet 4.5, GPT-4o oder Gemini 2.5 Pro
- Open Source S-Tier? → GLM-5, Kimi K2.5, MiniMax M2.5 (brauchen grosse GPU oder Cloud-Hosting)
Unser Stack
# Wir nutzen (Stand März 2026):
# - mistral-small3.2:24b auf RTX 3090 (.90) für Chat/Code (stark bei Deutsch)
# - mxbai-embed-large auf RTX 2060 (.99) für Embeddings (1024 dim)
# - Cloud API (Claude Sonnet 4.5) für komplexes Reasoning
# docker-compose.yml Auszug
services:
ollama:
image: ollama/ollama:latest
volumes:
- ollama_data:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# Environment Variables
OLLAMA_HOST=0.0.0.0:11434
OLLAMA_MODELS=/root/.ollama/modelsQuellen
- Artificial Analysis LLM Leaderboard, März 2026 — Intelligence Index, 312 Modelle, Updates alle 72h
- Onyx Open LLM Leaderboard — Kimi K2.5 HumanEval 99%, AIME 96.1%
- Vellum: Llama 3.3 70B vs GPT-4o — MMLU, HumanEval, IFEval Benchmarks
- Mistral AI: Mistral Small 3.1 — Übertrifft GPT-4o Mini bei europäischen Sprachen
- LocalAIMaster: Best GPUs for AI — RTX 3090 tok/s Messwerte
- CoreLab: LLM GPU Benchmarks — 8B ~112 tok/s auf RTX 3090
- IntuitionLabs: 24GB GPU Optimization — Max ~34B auf 24 GB VRAM
- Ollama Model Library — Verfügbare Modelle und Quantisierungen
- LMSYS Chatbot Arena — Community-basiertes Modell-Ranking
War dieser Artikel hilfreich?
Nächster Schritt: Workflows sauber in Betrieb bringen
Nutze bewährte n8n-Patterns, Templates und Integrationen für Workflows, die lokal, dokumentiert und auditierbar bleiben.
Warum AI Engineering
- Lokal und self-hosted gedacht
- Dokumentiert und auditierbar
- Aus eigener Runtime entwickelt
- Made in Austria
Kein Ersatz für Rechtsberatung.