Memory Management Pattern
Wie AI-Agenten persistentes Wissen speichern und abrufen.
AI-Agenten vergessen alles zwischen Sessions. Memory Management löst das durch 3 Stufen: CLAUDE.md (einfach, 0ms Latenz), Topic Files (mittlere Komplexität, ~50K Tokens), Knowledge Graphs mit Vektordatenbanken (unbegrenzt, ~200ms Latenz). Für 90% der Projekte reicht CLAUDE.md. Erst bei großen Wissensbasen brauchst du ChromaDB oder pgvector.
Das Problem
Jeder API-Call ist eine leere Session. Dein Agent weiß nicht, was gestern passiert ist. Memory Management löst dieses Problem durch strukturierte Persistenz.

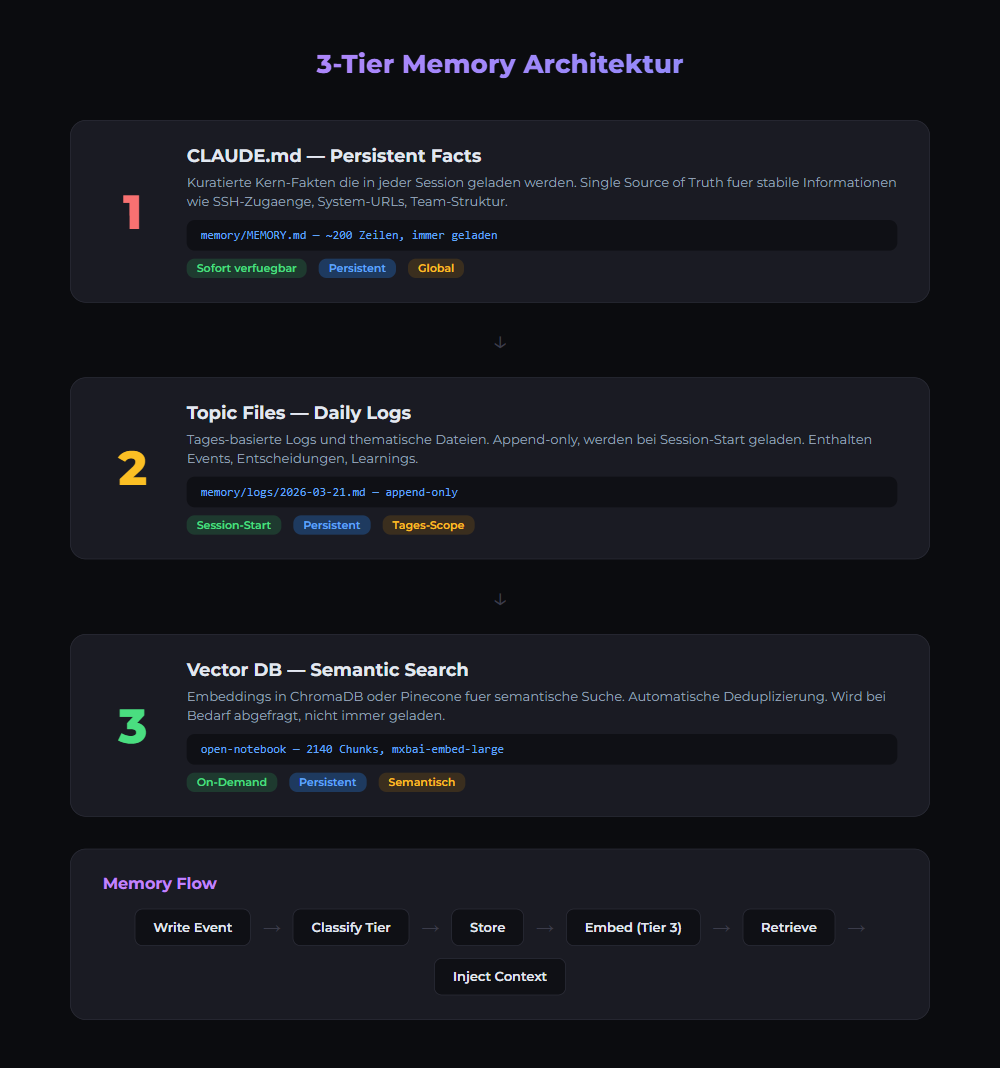
Das Drei-Stufen-Memory-System in der Praxis
Ein produktives Memory-System löst das Vergessens-Problem mit drei Stufen, die zusammenspielen: Kernwissen (immer geladen), Tagesprotokolle (Session-Historie) und optionale Vector Memory (semantische Suche).
Stufe 1: MEMORY.md — Das Kerngehirn
Die wichtigste Datei im System. Stell sie dir als das essentielle Briefing vor, das bei jedem einzelnen Start geladen wird. Was kommt hinein? Aktive Projekte und deren Status, wichtige Entscheidungen, aktuelle Business-Prioritäten, Links zu wichtigen Ressourcen.
Eine gute Faustregel: Wenn du ein neues Teammitglied in sechzig Sekunden briefen müsstest, was würdest du ihm sagen? Das gehört in MEMORY.md. Wichtige Regel: Unter zweihundert Zeilen halten — eine aufgeblähte Memory-Datei verschwendet Tokens und verwässert die wichtigen Informationen.
Stufe 2: Tagesprotokolle — Die Aktivitätsaufzeichnung
Während MEMORY.md das "was jetzt wichtig ist" speichert, speichern Tagesprotokolle das "was an jedem Tag passiert ist". Ein Arbeitstagebuch, das sich von selbst schreibt: Erledigte Aufgaben, getroffene Entscheidungen, erstellte Inhalte.
Tagesprotokolle ermöglichen eine durchsuchbare Historie ("Woran habe ich letzten Dienstag gearbeitet?"), füttern Weekly-Review-Skills und sorgen für Kontinuität — die nächste Session kann genau dort weitermachen, wo die letzte aufgehört hat.
Stufe 3: Vector Memory — Semantische Suche
Optional, aber leistungsfähig. Vector Memory ermöglicht semantische Suche über angesammeltes Wissen — basierend auf Bedeutung, nicht nur auf Schlüsselwörtern. Du kannst fragen "Was war unser Ansatz für Kunden-Onboarding?" und das System findet relevante Informationen, selbst wenn die genauen Worte nicht übereinstimmen.
Context-Dateien: Permanentes Grundwissen
Memory speichert, was im Laufe der Zeit passiert. Context-Dateien speichern die permanenten Grundlagen — die Dinge am Business, die sich nicht von Tag zu Tag ändern:
- my-business.md — Firmenprofil, Mission, Zielkunden, Umsatzmodell
- my-voice.md — Kommunikationsstil, Ton, Beispiel-Inhalte
- my-products.md — Produktkatalog, Preise, Features, Differenzierung
Die Voice-Datei löst die grösste Beschwerde über AI-generierten Content: dass er generisch und roboterhaft klingt. Je mehr Details du hineinsteckst — einschliesslich Beispielen deines tatsächlichen Schreibstils — desto authentischer wird der Output.
Technische Implementierungen
1. CLAUDE.md / PROJECT.md
Die einfachste Methode: Eine Markdown-Datei im Projektwurzelverzeichnis, die alle wichtigen Infos enthält. Wird bei jedem Run automatisch geladen.
# Project Context - Stack: Ollama + n8n + PostgreSQL - Zielgruppe: KMUs in Österreich - aktuelle Tasks: ... # Entscheidungen - Docker Compose für Deployment - PostgreSQL für Datenhaltung # Wichtige Files - /src/api - REST Endpoints - /tests - pytest Suite
2. Topic Files
Für komplexere Projekte: Mehrere Markdown-Dateien in einem /docs Verzeichnis. Jede Datei behandelt ein Thema (Architektur, API, Deployment, etc.).
/docs/
├── ARCHITEKTUR.md # System-Übersicht
├── API.md # Endpoints, Auth
├── DEPLOYMENT.md # CI/CD, Server
└── ENTSCHEIDUNGEN.md # Projekt-Geschichten3. Knowledge Graphs
Für Wissensbasen mit Millionen von Tokens: Vector-Datenbanken wie pgvector oder ChromaDB. Speichere Dokumente, Code, Logs als Embeddings und finde sie mit natürlicher Sprache.
4. Session Memory (Kurzzeit)
# Python: Session Memory mit SQLite
import sqlite3
def save_session(agent_id, messages):
conn = sqlite3.connect('memory.db')
conn.execute(
"INSERT INTO sessions VALUES (?, ?, datetime('now'))",
(agent_id, json.dumps(messages))
)
conn.commit()
def load_session(agent_id):
# Lade letzte 10 Nachrichten
return conn.execute(
"SELECT messages FROM sessions WHERE agent_id=? ORDER BY created DESC LIMIT 1",
(agent_id,)
).fetchone()Wann was verwenden?
| Methode | Tokens | Latenz | Komplexität |
|---|---|---|---|
| CLAUDE.md | ~8K | 0ms | Minimal |
| Topic Files | ~50K | ~50ms | Niedrig |
| Knowledge Graph | Unlimited | ~200ms | Hoch |
| Session Memory | ~32K | ~10ms | Mittel |
Beispiel: ChromaDB für Vektorspeicher
Wenn dein Wissen über 50K Tokens hinausgeht, speichere Dokumente als Embeddings und suche per Ähnlichkeit:
# ChromaDB: Vektorspeicher für Agent-Memory
import chromadb
# Client erstellen (persistent)
client = chromadb.PersistentClient(path="./chroma_data")
# Collection anlegen
collection = client.get_or_create_collection(
name="agent_knowledge",
metadata={"hnsw:space": "cosine"}
)
# Dokumente speichern
collection.add(
documents=[
"PostgreSQL läuft auf Port 5432 im Docker Swarm",
"Ollama braucht GPU-Node docker-swarm3",
"Backup läuft täglich um 02:00 via Restic",
],
ids=["doc1", "doc2", "doc3"],
metadatas=[
{"category": "infra"},
{"category": "ai"},
{"category": "ops"},
]
)
# Ähnlichkeitssuche
results = collection.query(
query_texts=["Wo läuft die Datenbank?"],
n_results=2
)
print(results["documents"])
# → [["PostgreSQL läuft auf Port 5432 im Docker Swarm", ...]]Beginne mit CLAUDE.md. Das reicht für 90% der Projekte. Erst wenn du wirklich eine Wissensbasis aufbaust, die größer als 50K Tokens ist, brauchst du Vektordatenbanken wie ChromaDB oder pgvector.
Memory sauber halten
Memory-Pflege ist wie einen aufgeräumten Schreibtisch zu halten. Ohne regelmässiges Aufräumen werden wichtige Dinge unter Stapeln veralteter Informationen begraben.
- Die Zweihundert-Zeilen-Regel für MEMORY.md ist die wichtigste — ältere Einträge ins Tagesprotokolle-Archiv verschieben
- MEMORY.md fokussiert auf aktuelle Prioritäten, aktive Projekte und essentielle Referenzinformationen halten
- Tagesprotokolle werden automatisch nach Datum organisiert — einmal im Monat ältere Protokolle archivieren
- Keine Secrets, Credentials oder API Keys in Memory-Dateien speichern
Der echte Nutzen: Kontinuität
So sieht Memory Management in der Praxis aus: Montag erzählst du dem System von einem neuen Kundenprojekt — die Details werden im Tagesprotokoll gespeichert und das Projekt als aktiv in MEMORY.md markiert. Dienstag bittest du um ein Angebot — das System kennt die Details bereits und schreibt in deiner Markenstimme. Mittwoch kommt Kundenfeedback, Donnerstag kannst du nach dem Projektstatus fragen und bekommst eine komplette Zusammenfassung über alle Tage hinweg.
Kontinuität, Kontext und Erinnerung — die drei Dinge, die eine AI vom Tool zum verlässlichen Teammitglied machen.
Quellen
- Anthropic: Claude Code Memory — Offizielle Dokumentation zu CLAUDE.md
- Claude Code Repository — CLAUDE.md Spezifikation und Beispiele
- ChromaDB Dokumentation — Open-Source Vektordatenbank
- pgvector — Vektor-Extension für PostgreSQL
War dieser Artikel hilfreich?
Nächster Schritt: vom Wissen in die Umsetzung
Wenn du mehr willst als Theorie: Setups, Workflows und Vorlagen aus dem echten Betrieb für Teams, die lokale und dokumentierte AI-Systeme wollen.
- Lokal und self-hosted gedacht
- Dokumentiert und auditierbar
- Aus eigener Runtime entwickelt
- Made in Austria